
MySQL的crash-safe原理解析
MySQL作为当下最流行的开源关系型数据库,有一个很症结和根本的才能,便是必需可以或许保证数据不会丢。那么在这个才能背后,MySQL是若何设计能力保证不管在什么光阴瓦解,规复后都能保证数据不会丢呢。有哪些症结技术支持了这个才能。本文将为我们逐一揭晓。
一、前言
MySQL 保证数据不会丢的才能主要体如今两方面:
可以或许规复到任何光阴点的状况;
可以或许保证MySQL在任何光阴段突然奔溃,重启后之条件交的记载都不会丧失;
对付第一点将MySQL规复到任何光阴点的状况,信任许多人都知道,只要保存有足够的binlog,就能经由过程重跑binlog来实现。
对付第二点的才能,也便是本文题目所讲的crash-safe。即在 InnoDB 存储引擎中,事务提交进程中任何阶段,MySQL突然奔溃,重启后都能保证事务的完备性,已提交的数据不会丧失,未提交完备的数据会主动进行回滚。这个才能依附的便是redo log和unod log两个日记。
由于crash-safe主要体如今事务执行进程中突然奔溃,重启后能保证事务完备性,以是在讲授详细原理之前,先相识下MySQL事务执行有哪些症结阶段,后面能力根据这几个阶段来进行解析。下面以一条更新语句的执行流程为例,话不多说,直接上图:
从上图可以清楚地看出一条更新语句在MySQL中是怎么执行的,简单进行总结一下:
从内存中找出这条数据记载,对其进行更新;
将对数据页的变动记载到redo log中;
将逻辑操作记载到binlog中;
对付内存中的数据和日记,都是由后台线程,当触发到落盘规矩后再异步进行刷盘;
上面演示了一条更新语句的具体执行进程,接下来咱们经由过程解答问题,带着问题来剖析这个crash-safe的设计原理。
二、WAL机制
问题:为什么不直接变动磁盘中的数据,而要在内存中变动,然后还必要写日记,末了再落盘这么繁杂。
这个问题信任许多同窗都能猜出来,MySQL变动数据的时刻,之以是不直接写磁盘文件中的数据,最主要便是机能问题。由于直接写磁盘文件是随机写,开销年夜机能低,没方法满意MySQL的机能要求。以是才会设计成先在内存中对数据进行变动,再异步落盘。然则内存老是弗成靠,万一断电重启,还没来得及落盘的内存数据就会丧失,以是还必要加上写日记这个步调,万一断电重启,还能经由过程日记中的记载进行规复。
写日记固然也是写磁盘,然则它是次序写,相比随机写开销更小,能晋升语句执行的机能(针对次序写为什么比随机写更快,可以比方为你有一个簿子,依照次序一页一页写确定比写一个字都要找到对应页写快得多)。
这个技术便是年夜多半存储体系根本都邑用的WAL(Write Ahead Log)技术,也称为日记先行的技术,指的是对数据文件进行改动前,必需将改动先记载日记。保证了数据同等性和持久性,而且晋升语句执行机能。
三、焦点日记模块
问题:更新SQL语句执行流程中,统共必要写3个日记,这3个是不是都必要,能不克不及进行简化。
更新SQL执行进程中,统共涉及MySQL日记模块此中的三个焦点日记,分离是redo log(重做日记)、undo log(回滚日记)、binlog(归档日记)。这里提前预报,crash-safe的才能主要依附的便是这三年夜日记。
接下来,针对每个日记将零丁先容各自的作用,然后再来评估是否能简化失落。
1、重做日记 redo log
redo log也称为事务日记,由InnoDB存储引擎层发生。记载的是数据库中每个页的改动,而不是某一行或某几行改动成怎样,可以用来规复提交后的物理数据页(规复数据页,且只能规复到末了一次提交的地位,由于改动会笼罩之前的)。
前面提到的WAL技术,redo log便是WAL的典型利用,MySQL在有事务提交对数据进行变动时,只会在内存中改动对应的数据页和记载redo log日记,完成后即表现事务提交胜利,至于磁盘数据文件的更新则由后台线程异步处置。因为redo log的参加,保证了MySQL数据同等性和持久性(纵然数据刷盘之前MySQL奔溃了,重启后仍旧能经由过程redo log里的变动记载进行重放,从新刷盘),此外还能晋升语句的执行机能(写redo log是次序写,相比于更新数据文件的随机写,日记的写入开销更小,能明显晋升语句的执行机能,进步并发量),由此可见redo log是必弗成少的。
redo log是固定年夜小的,以是只能轮回写,从头开端写,写到末端就又回到开首,相称于一个环形。当日记写满了,就必要对旧的记载进行擦除,但在擦除之前,必要确保这些要被擦除记载对应在内存中的数据页都已经刷到磁盘中了。在redo log满了到擦除旧记载腾出新空间这段时代,是不克不及再接管新的更新哀求,以是有可能会导致MySQL卡顿。(以是针对并发量年夜的体系,恰当设置redo log的文件年夜小异常紧张。。。)
2、回滚日记 undo log
undo log顾名思义,主要便是提供了回滚的作用,但其还有另一个主要作用,便是多个行版本节制(MVCC),保证事务的原子性。在数据改动的流程中,会记载一条与当前操作相反的逻辑日记到undo log中(可以以为当delete一笔记录时,undo log中会记载一条对应的insert记载,反之亦然,当update一笔记录时,它记载一条对应相反的update记载),假如由于某些缘故原由导致事务非常失败了,可以借助该undo log进行回滚,保证事务的完备性,以是undo log也必弗成少。
3、归档日记 binlog
binlog在MySQL的server层发生,不属于任何引擎,主要记载用户对数据库操作的SQL语句(除了查询语句)。之以是将binlog称为归档日记,是由于binlog不会像redo log一样擦失落之前的记载轮回写,而是一直记载(跨越有用期才会被清算),假如跨越单日记的最年夜值(默认1G,可以经由过程变量 max_binlog_size 设置),则会新起一个文件继续记载。但因为日记可能是基于事务来记载的(如InnoDB表类型),而事务是绝对弗成能也不该该跨文件记载的,假如恰好binlog日记文件到达了最年夜值但事务还没有提交则不会切换新的文件记载,而是继续增年夜日记,以是 max_binlog_size 指定的值和现实的binlog日记年夜小纷歧定相等。
恰是因为binlog有归档的作用,以是binlog主要用作主从同步和数据库基于光阴点的还原。
那么回到适才的问题,binlog可以简化失落吗。这里必要分场景来看:
假如是主从模式下,binlog是必需的,由于从库的数据同步依附的便是binlog;
假如是单机模式,而且不斟酌数据库基于光阴点的还原,binlog就不是必需,由于有redo log就可以保证crash-safe才能了;但假如万一必要回滚到某个光阴点的状况,这时刻就力所不及,以是建议binlog照样一直开启;
依据上面临三个日记的详解,我们可以对这个问题进行解答:在主从模式下,三个日记都是必需的;在单机模式下,binlog可以视环境而定,保险起见最好开启。
四、两阶段提交
问题:为什么redo log要分两步写,中央再穿插写binlog呢。
从上面可以看出,由于redo log影响主库的数据,binlog影响从库的数据,以是redo log和binlog必需坚持同等能力保证主从数据同等,这是条件。
信任许多有过开发履历的同窗都知道散布式事务,这里的redo log和binlog实在便是很典型的散布式事务场景,由于两者自己便是两个自力的个别,要想坚持同等,就必需使用散布式事务的办理计划来处置。而将redo log分成了两步,实在便是使用了两阶段提交协定(Two-phase Commit,2PC)。
下面临更新语句的执行流程进行简化,看一下MySQL的两阶段提交是若何实现的:
从图中可看出,事务的提交进程有两个阶段,便是将redo log的写入拆成了两个步调:prepare和commit,中央再穿插写入binlog。
假如这时刻你很疑惑,为什么必定要用两阶段提交呢,假如不消两阶段提交会呈现什么环境,好比先写redo log,再写binlog或者先写binlog,再写redo log不行吗。下面我们用反证法来进行论证。
我们继续用update T set c=c+1 where id=2这个例子,假设id=2这一条数据的c初始值为0。那么在redo log写完,binlog还没有写完的时刻,MySQL过程非常重启。因为redo log已经写完了,体系重启后会经由过程redo log将数据规复回来,以是规复后这一行c的值是1。然则因为binlog没写完就crash了,这时刻binlog里面就没有记载这个语句。是以,不管是如今的从库照样之后经由过程这份binlog还原暂时库都没有这一次更新,c的值照样0,与原库的值分歧。
同理,假如先写binlog,再写redo log,半途体系crash了,也会导致主从纷歧致,这里就不再胪陈。
以是将redo log分成两步写,即两阶段提交,能力保证redo log和binlog内容同等,从而保证主从数据同等。
两阶段提交固然可以或许保证单事务两个日记的内容同等,但在多事务的环境下,却不克不及保证两者的提交次序同等,好比下面这个例子,假设如今有3个事务同时提交:
T1 ( --prepare--binlog---------------------commit)
T2 ( -----prepare-----binlog----commit)
T3 ( --------prepare-------binlog------commit)
解析:
redo log prepare的次序:T1 --》T2 --》T3
binlog的写入次序:T1 --》 T2 --》T3
redo log commit的次序:T2 --》 T3 --》T1
结论:因为 binlog写入的次序和 redo log提交停止的次序纷歧致,导致 binlog和 redo log所记载的事务提交停止的次序纷歧样,终极导致的成果便是主从数据纷歧致。
是以,在两阶段提交的流程根基上,还必要加一个锁来保证提交的原子性,从而保证多事务的环境下,两个日记的提交次序同等。以是在早期的MySQL版本中,经由过程使用prepare_commit_mutex锁来保证事务提交的次序,在一个事务获取到锁时能力进入prepare,一直到commit停止能力开释锁,下个事务才可以继续进行prepare操作。经由过程加锁固然完善地办理了次序同等性的问题,但在并发量较年夜的时刻,就会导致对锁的争用,机能欠安。除了锁的争用会影响到机能之外,还有一个对机能影响更年夜的点,便是每个事务提交都邑进行两次fsync(写磁盘),一次是redo log落盘,另一次是binlog落盘。年夜家都知道,写磁盘是昂贵的操作,对付通俗磁盘,每秒的QPS年夜概也便是几百。
五、组提交
问题:针对经由过程在两阶段提交中加锁节制事务提交次序这种实现方式遇到的机能瓶颈问题,有没有更好的办理计划呢。
谜底天然是有的,在MySQL 5.6 就引入了binlog组提交,即BLGC(Binary Log Group Commit)。binlog组提交的根本思惟是,引入行列步队机制保证InnoDB commit次序与binlog落盘次序同等,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目标。详细如图:
第一阶段(prepare阶段):
持有prepare_commit_mutex,而且write/fsync redo log到磁盘,设置为prepared状况,完成后就开释prepare_commit_mutex,binlog不作任何操作。
第二个阶段(commit阶段):这里拆分成了三步,每一步的义务分派给一个专门的线程处置:
Flush Stage(写入binlog缓存)
① 持有Lock_log mutex [leader持有,follower期待]
② 获取行列步队中的一组binlog(行列步队中的所有事务)
③ 写入binlog缓存
Sync Stage(将binlog落盘)
①开释Lock_log mutex,持有Lock_sync mutex[leader持有,follower期待]
②将一组binlog落盘(fsync动作,最耗时,假设sync_binlog为1)。
Commit Stage(InnoDB commit,清晰undo信息)
①开释Lock_sync mutex,持有Lock_commit mutex[leader持有,follower期待]
② 遍历行列步队中的事务,一一进行InnoDB commit
③ 开释Lock_commit mutex
每个Stage都有本身的行列步队,行列步队中的第一个事务称为leader,其他事务称为follower,leader节制着follower的行动。每个行列步队各自有mutex掩护,行列步队之间是次序的。只有flush完成后,能力进入到sync阶段的行列步队中;sync完成后,能力进入到commit阶段的行列步队中。然则这三个阶段的功课是可以同时并发执行的,即当一组事务在进行commit阶段时,其他新事务可以进行flush阶段,实现了真正意义上的组提交,年夜幅度低落磁盘的IOPS耗费。
针对组提交为什么比两阶段提交加锁机能更好,简单做个总结:组提交固然在每个行列步队中仍旧保存了prepare_commit_mutex锁,然则锁的粒度变小了,酿成了本来两阶段提交的1/4,以是锁的争用性也会年夜年夜低落;另外,组提交是批量刷盘,相比之前的单笔记录都要刷盘,能年夜幅度低落磁盘的IO耗费。
六、数据规复流程
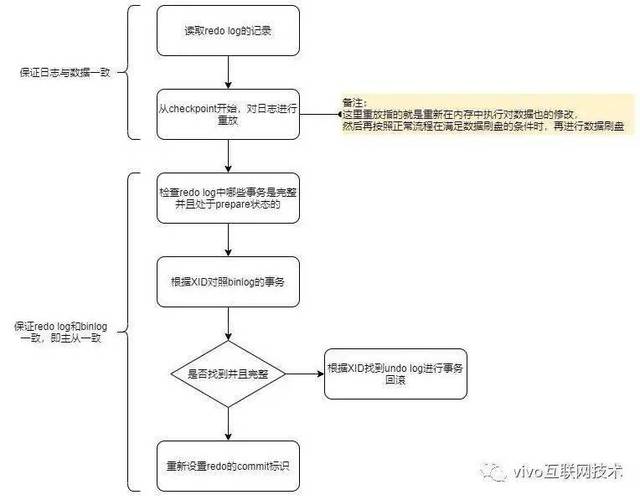
问题:假设事务提交进程中,MySQL过程突然奔溃,重启后是怎么保证数据不丧失的。
下图便是MySQL重启后,提供服务前会先做的事 -- 规复数据的流程:
对上图进行简单描写便是:奔溃重启后会反省redo log中是完备而且处于prepare状况的事务,然后依据XID(事务ID),从binlog中找到对应的事务,假如找不到,则回滚;找到而且事务完备则从新commit redo log,完成事务的提交。
下面我们依据事务提交流程,在分歧的阶段时候,看看MySQL突然奔溃后,依照上述流程是若何规复数据的。
时候A(刚在内存中变动完数据页,还没有开端写redo log的时刻奔溃):
由于内存中的脏页还没刷盘,也没有写redo log和binlog,即这个事务还没有开端提交,以是奔溃规复跟该事务没有关系;
时候B(正在写redo log或者已经写完redo log而且落盘后,处于prepare状况,还没有开端写binlog的时刻奔溃):
规复后会断定redo log的事务是不是完备的,假如不是则依据undo log回滚;假如是完备的而且是prepare状况,则进一步断定对应的事务binlog是不是完备的,假如不完备则一样依据undo log进行回滚;
时候C(正在写binlog或者已经写完binlog而且落盘了,还没有开端commit redo log的时刻奔溃):
规复后会跟时候B一样,先反省redo log中是完备而且处于prepare状况的事务,然后断定对应的事务binlog是不是完备的,假如不完备则一样依据undo log回滚,完备则从新commit redo log;
时候D(正在commit redo log或者事务已经提交完的时刻,还没有反馈胜利给客户真个时刻奔溃):
规复后跟时候C根本一样,都邑对比redo log和binlog的事务完备性,来确认是回滚照样从新提交。
七、总结
至此对MySQL 的crash-safe原理细节就根本讲完了,简单回想一下:
起首简单先容了WAL日记先行技术,包含它的界说、流程和作用。WAL是年夜部门数据库体系实现同等性和持久性的通用设计模式。;
接着对MySQL的日记模块,redo log、undo log、binlog、两阶段提交和组提交都进行了具体先容;
末了讲授了数据规复流程,并从分歧时候加以验证。